
Randomized Smoothing; An Introduction to Certified ML
یک مسئله جالب در یادگیری ماشین، یادگیری ماشین تضمین شده (Certified) است. این مسئله به ما میگوید یک شبکه عصبی که چیزی جز یک Function Approximator نیست، اگر به ازای ورودی جواب درستی میدهد؛ آیا تضمینی برای درستی جواب به ازای برای دلتاهای کوچک میدهد یا خیر؟
در این متن قرار است کار آقای cohen را بررسی کنیم .میتوانید به این لینک نیز برای بررسی دقیقتر مراجعه کنید.
از آنجایی که به ازای هر دلخواه، ما نمیتوانیم تئوری خاصی بدهیم، یک ایده جالب برای صحبت کردن به صورت کلی انجام میدهیم. فرض کنید به ازای هر تابع ورودی دلخواه شما نتیجه آن یا را خروجی ندهید و بهجای آن، به ازای بینهایت نقطه کلاسی که بیشترین بار تکرار می شود (احتمال بالاتری دارد) را خروجی دهید. دقت کنید که این رویکرد به ازای هر تابع دلخواهی قابل انجام است.
درواقع ما یک تابع جدید به اسم میسازیم بهطوری که آنرا میتوان بهصورت تعریف کرد که میآید. در واقع ما تابع را نرم (smooth) کردهایم . در تصویر زیر عملا این smooth کردن را می توانید مشاهده کنید.
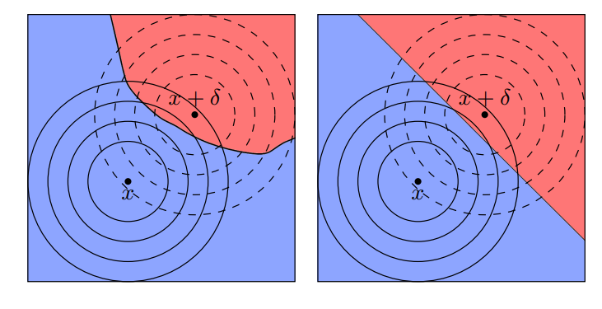
تابع جدید ما خواص جالبی دارد. یک خاصیت جالب که cohen et. al آن را ثابت کرد این است که این تابع در یک شعاع، مقاوم (Robust) است؛ به این معنی که اگر در نتیجه درستی بدهد، در هایی که باشد نیز مقاوم است. شاید برایتان سوال باشد این مقدار چه چیزی است؟ Cohen et. al اثبات کرده است که این شعاع برابر با
است که در این فرمول و احتمال دو محتملترین کلاسها هستند و تابع توزیع تجمیعی معکوس توزیع نرمال است.
برای تخمین زدن احتمالهای دو کلاس محتمل میتوان از روشهای monte carlo و نمونهبرداری استفاده کرد. در عمل اضافهکردن نویز و آموزشدادن مدلها با نویز، یک روش موثر برای ساختن مدلهای robust نسبت به حملهها به شبکههای عصبی هستند. (کافی است را از روی دلخواه بسازید و به صورت اثبات پذیر می دانیم مقاوم است)